 Paper
Paper
 Code
Code
 Data
Data
 BibTeX
BibTeX
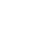
How would the sound in a studio change with a carpeted floor and acoustic tiles on the walls? We introduce the task of material-controlled acoustic profile generation, where, given an indoor scene with specific audio-visual characteristics, the goal is to generate a target acoustic profile based on a user-defined material configuration at inference time. We address this task with a novel encoder-decoder approach that encodes the scene’s key properties from an audio-visual observation and generates the target Room Impulse Response (RIR) conditioned on the material specifications provided by the user. Our model enables the generation of diverse RIRs based on various material configurations defined dynamically at inference time. To support this task, we create a new benchmark, the Acoustic Wonderland Dataset, designed for developing and evaluating material-aware RIR prediction methods under diverse and challenging settings. Our results demonstrate that the proposed model effectively encodes material information and generates high-fidelity RIRs, outperforming several baselines and state-of-the-art methods. Code and dataset will be released soon.
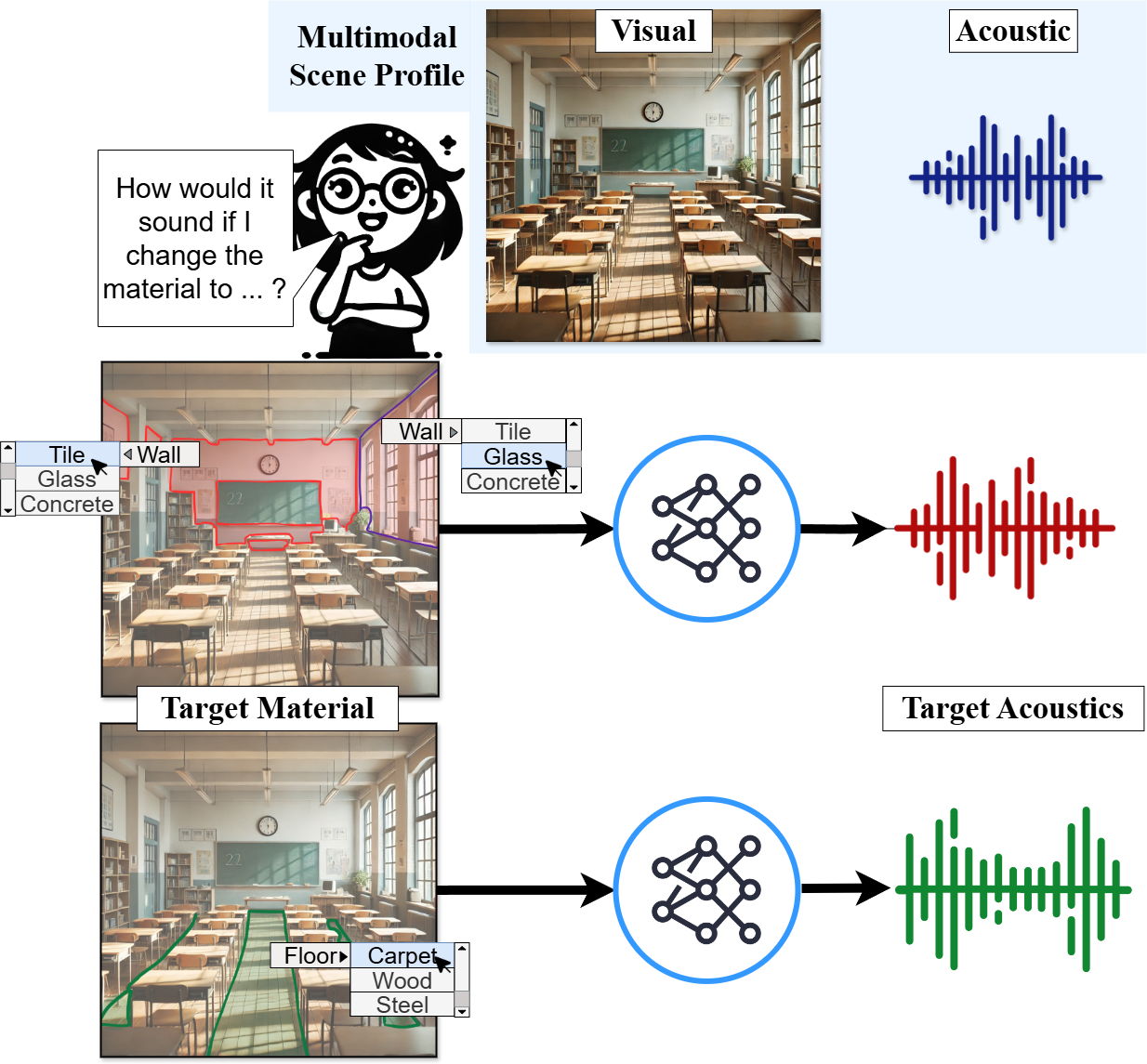
Each sample in the Acoustic Wonderland dataset contains audio-visual observations from a 3D scene. Each datapoint consists of RGB and semantic scene observations. Every semantic object is mapped to a material, represented in the material mask. Every material mapping of the scene is captured acoustically in the binaural RIR.
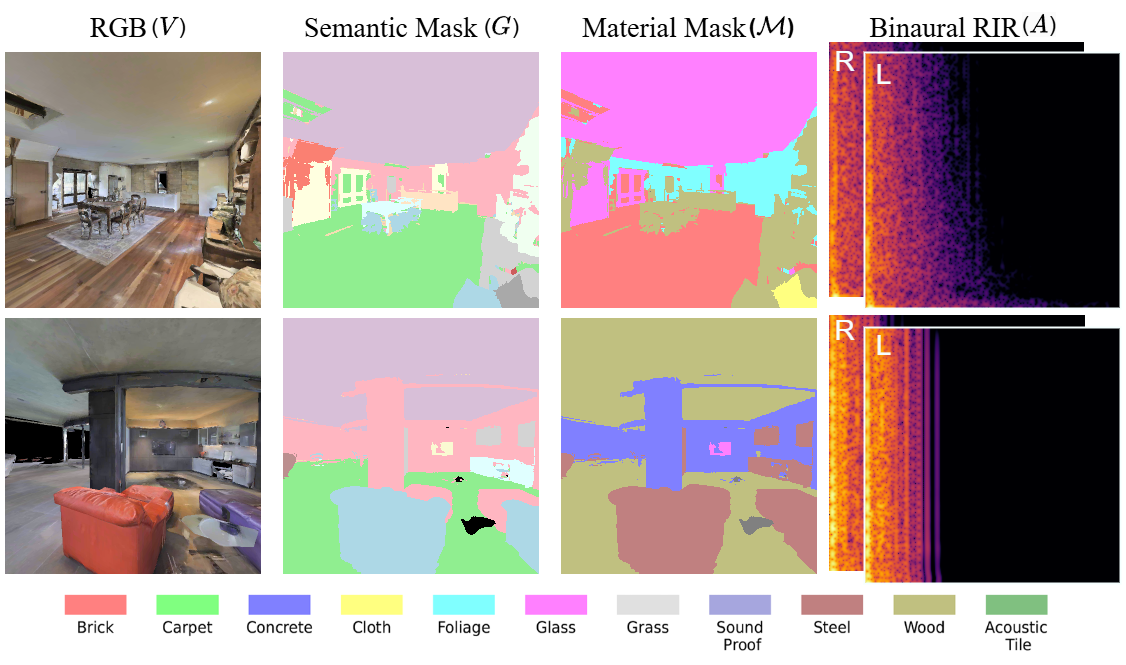
Given an audio-visual observation from the scene, the model encodes key visual and acoustic properties using a multimodal scene encoder. For a given arbitrary target material assignment, the model then generates a weighting and residual to adjust source audio with a new reverbeation pattern compatible with new material assignment - thereby predicting the target RIR